We've advertised Supermaven as the first code completion tool with a 300,000-token context window. But a long context window doesn't mean much unless you can make productive use of those tokens to improve suggestions. After all, the LSTM layer has been around for decades and can easily consume an arbitrarily long context without performance issues, but it's not useful because it can only remember the last couple hundred tokens.
So how does Supermaven perform?
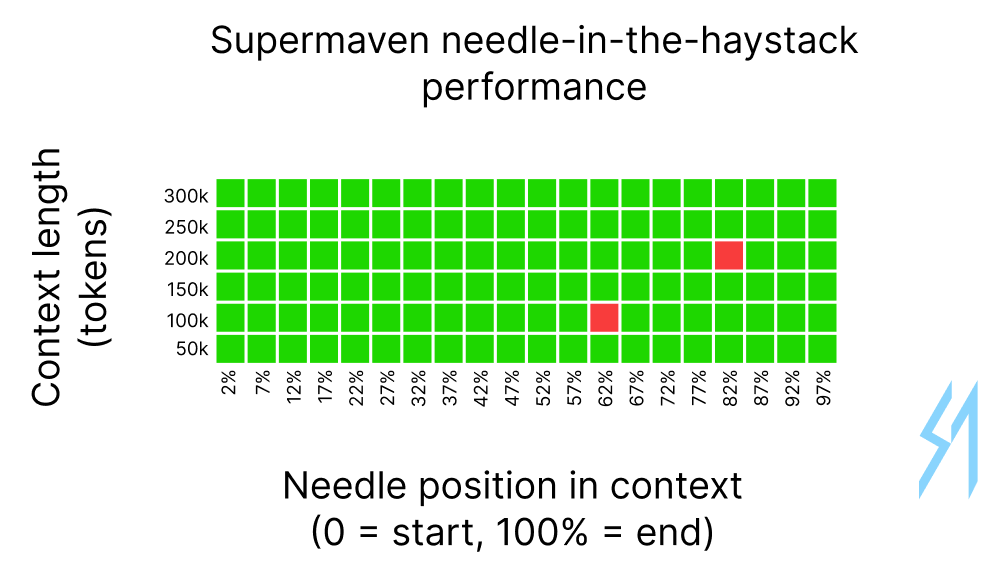
Needle In A Haystack
A common benchmark for long-context performance is the "needle in a haystack" test, where the model is given a long text with a particular piece of information hidden part-way through, and it's asked to retrieve the information after it's consumed the entire text.
We implemented this test by taking N tokens of our internal code (where N ranges from 50,000 to 300,000) and inserting a "needle" within the code that looks like this:
// needle: vhmpphtv => 'oualsoki'
Here, vhmpphtv and oualsoki represent random strings of 8 lower-case letters. We use different random strings for each test. We insert the needle at varying positions within the code, then at the end we prompt the model as follows:
// needle: vhmpphtv => '
The test is marked as correct if the model returns the correct completion, which in this case is oualsoki'.
Below is the result of running this test for N = 50,000, 100,000, 150,000, 200,000, 250,000, and 300,000 tokens. We run the test 20 times for each value of N, placing the needle at a different position within the code each time.
Dense retrieval
The needle-in-a-haystack test is useful, but it's made artificially easier because the needle is noticeably different from the surrounding code, which encourages the model to remember the needle.
To give Supermaven a harder test, we created a task where the model is given a sequence of key-value pairs that look like this:
assert obj['tvdiqaac'] == 'm'
assert obj['qacbblfk'] == 'c'
# many tokens later...
assert obj['tvdiqaac'] == 'm'
# many tokens later...
assert obj['qacbblfk'] == 'c'This task is more challenging than the needle-in-a-haystack test because the model must remember everything it has seen in order to complete the task successfully, while the needle-in-a-haystack test only requires the model to remember the needle.
We construct the task as a sequence of random key-value pairs such that the total length of the sequence is 300,000 tokens. We design the sequence so that every key-value pair appears twice. On the second occurrence, we prompt the model as follows:
assert obj['tvdiqaac'] == '
The model is scored on whether it can recall the previous occurrence of the key (in this case, tvdiqaac) in order to complete the line with the correct value (m).
Below we plot the retrieval performance as a function of the number of tokens separating the first occurrence of the key-value pair from the second:
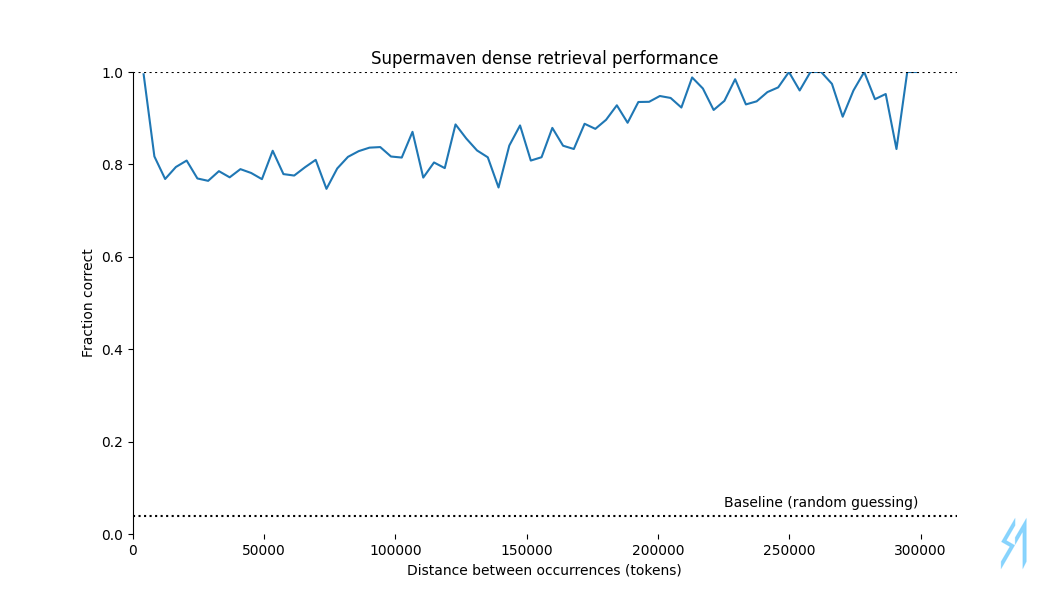
Many groups have found that LLMs are best at retrieving information that is close to the beginning or the end of a sequence, and we reproduce this finding in the plot above, with near-100% accuracy when the occurrences are separated by fewer than 10,000 or more than 290,000 tokens, while accuracy is lowest in the middle of the sequence, reaching around 75% when occurrences are separated by 50,000 tokens. (Random guessing would achieve 4% accuracy.)
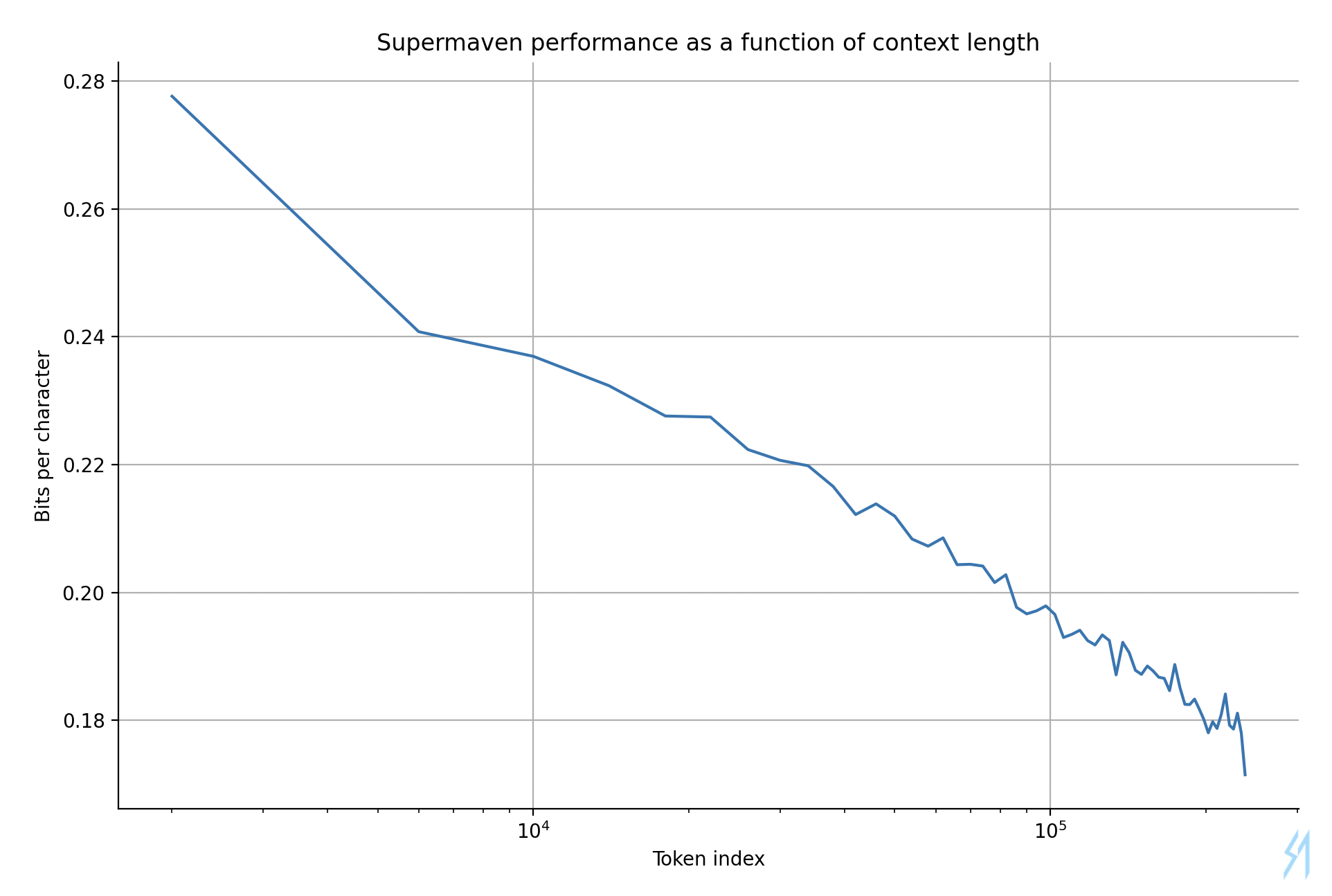
Prediction error vs. context length
In this last plot, we use our internal Supermaven code to obtain 240,000 tokens of out-of-sample data to evaluate the Supermaven model. We plot the prediction error on this data as a function of the token index within the code. The larger the token index, the more context the model has access to, and the lower the prediction error. To decrease noise, we averaged over 545 random orderings of the files to obtain the data in the plot.
The prediction error decreases smoothly as the token index increases, which shows the model is using the entire context to improve its predictions.