Four months ago, we launched Supermaven with the goal of creating the fastest and most context-aware copilot in the world. Your feedback has shaped Supermaven since then - recently we added in-editor chat, our most requested feature, which lets you use models like GPT-4o and Claude 3.5 Sonnet to write code in your editor. Thanks to your suggestions and support, over 20,000 developers now use Supermaven to write code more efficiently.
Today, we're announcing the most significant update yet to our inline completions. We've trained Babble, a new model, which is 2.5x larger than our previous model and expands its context window from 300,000 to 1 million tokens. Babble is trained on a larger corpus of code than our previous model, which gives it broader knowledge, while having even lower latency because of simultaneous improvements to our serving infrastructure.
To measure Babble's ability to make use of its context window, we performed some benchmarks:
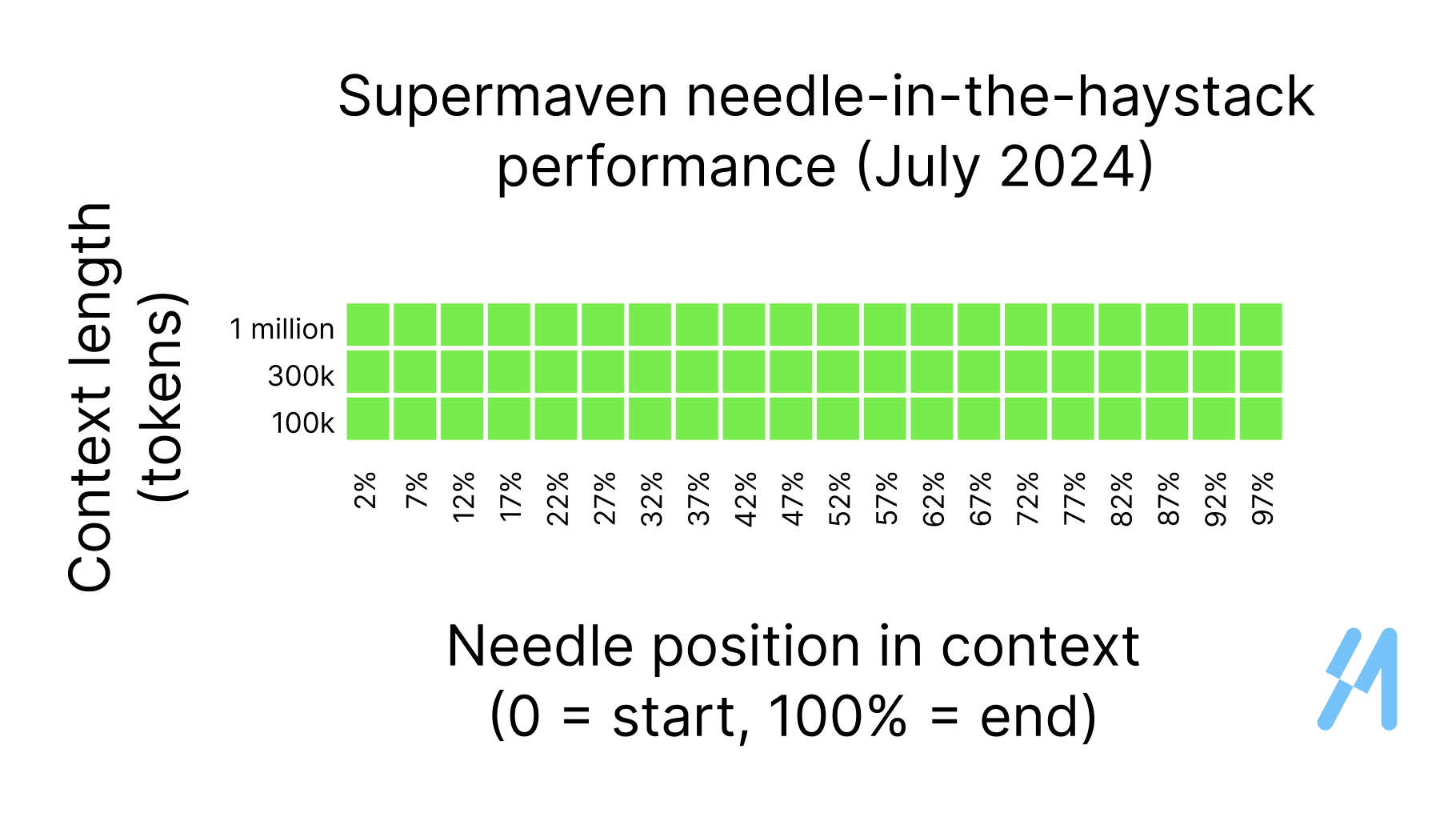
Needle in a haystack
To evaluate recall ability, we repeat the "needle in a haystack" test from our last benchmarking post. We use the same test, but with Babble instead of our previous model. We achieve 100% recall of the needle regardless of where it's hidden within the 1 million tokens of context.
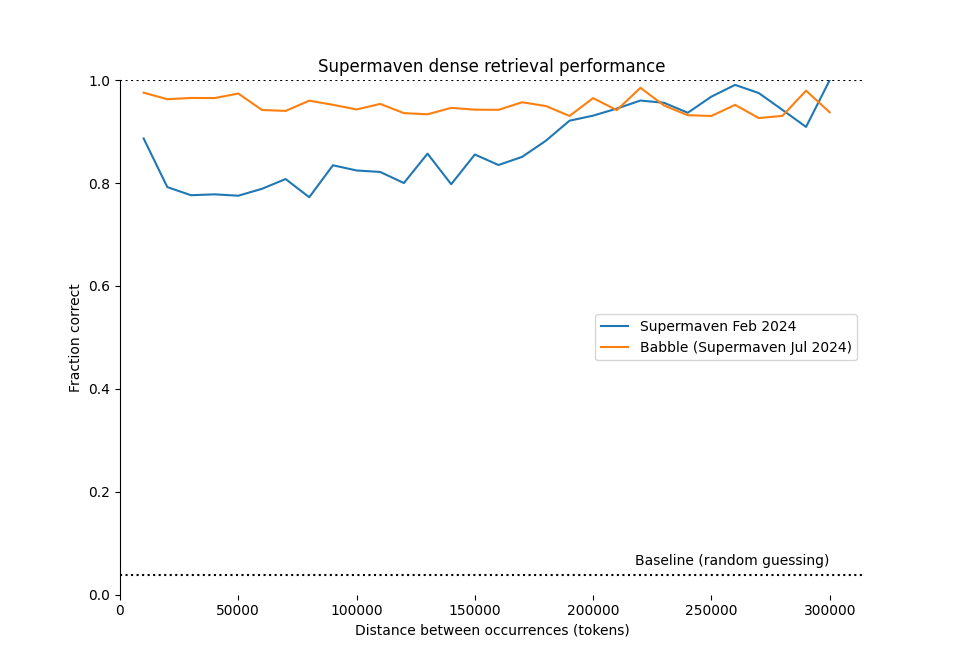
Dense retrieval
We also repeated the dense retrieval benchmark, where the model is given a sequence of key-value pairs that look like this:
assert obj['tvdiqaac'] == 'm'
assert obj['qacbblfk'] == 'c'
# many tokens later...
assert obj['tvdiqaac'] == 'm'
# many tokens later...
assert obj['qacbblfk'] == 'c'This task is more challenging than the needle-in-a-haystack test because the model must remember everything it has seen in order to complete the task successfully, while the needle-in-a-haystack test only requires the model to remember the needle.
We show the results compared to our previous model here:
Prediction error vs. context length
Finally, we plot the prediction loss as a function of the context size. Previously we evaluated this on our internal code to ensure it was out-of-sample, but we have less than 1 million tokens of internal code, so for this benchmark we evaluated on Python files in the PyTorch repository. To reduce noise, we restricted to files under 25 KB and averaged over 200 different orderings of the files. The results are shown here:
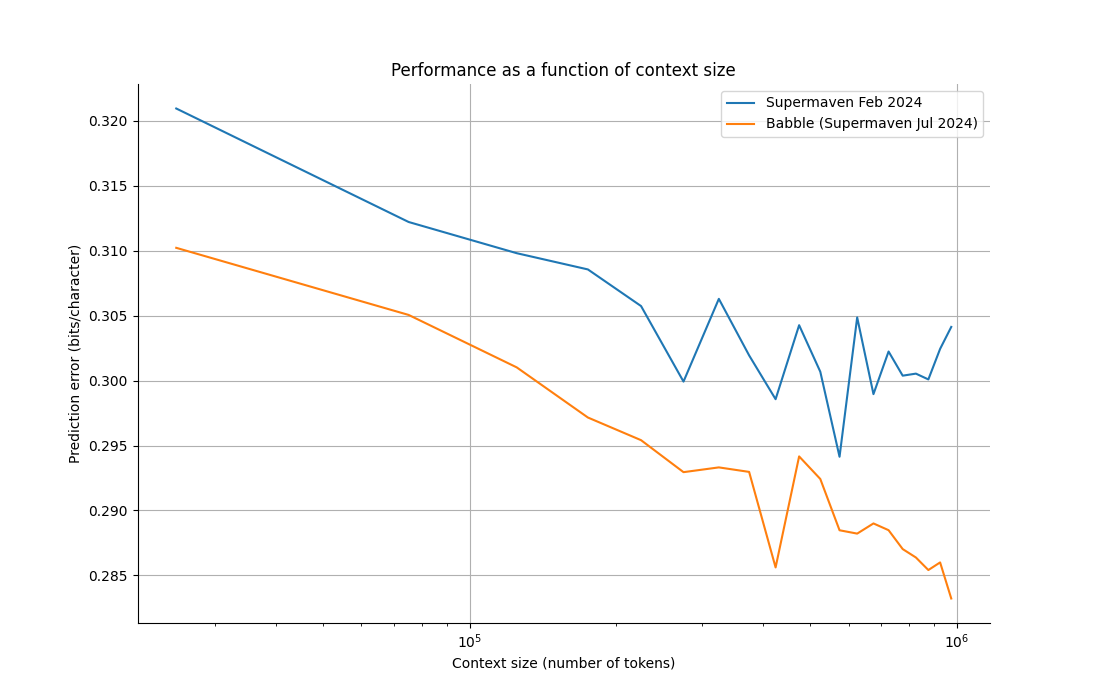
(As a baseline, we ran Llama 3 8B on the same data and got an average bits/character of 0.384 when scoring on the trailing 4,096 tokens of each 8,192-token window.)
Supermaven 1.0
Babble has already been deployed to all users, and Supermaven Pro users will be able to use its 1 million token context window moving forward. Besides Babble, we've made many other improvements to Supermaven in the past month:
- Team billing: easily manage your team's subscriptions and get a single monthly invoice for the entire team.
- Supermaven Chat: a convenient interface for using models like GPT-4o and Claude 3.5 Sonnet to write code.
- Improvements to our serving infrastructure to ensure consistently low latency.
We are calling this release "Supermaven 1.0" to reflect these substantial improvements. We're excited to hear your feedback as you use Supermaven 1.0 to accelerate your work!